 Lost Blue
Lost Blue Zale's Makeup
Zale's Makeup Night N Day Detailing
Night N Day Detailing Surfclub
Surfclub FungiReview
FungiReview NEST Divers
NEST Divers RSquare Games
RSquare Games Sleepless Advertising
Sleepless AdvertisingAWS Outage on October 20 Cripples Major Websites Across the U.S.
A widespread AWS outage on Oct 20, 2025 disrupted major sites across the U.S. Explore what happened, who was affected, and expert insights from CCS.

In the early hours of October 20, 2025, the digital world experienced a jarring reminder of its dependence on the cloud. Amazon Web Services (AWS), the backbone of a vast portion of the internet, suffered a major outage centered in its US-East-1 region (Northern Virginia). The disruption began around 3:11 a.m. ET, spreading rapidly and triggering widespread downtime for websites, apps, and digital services across the globe. By the time AWS had identified the root cause—a DNS failure affecting key load-balancing and database endpoints—millions of users were already locked out of their favorite platforms. A fix was deployed a few hours later, and by mid-morning, services were gradually restored, though many systems continued to suffer degraded performance as backlogs cleared.
The outage’s ripple effect was immense. Major online platforms such as Fortnite, Snapchat, and Venmo went offline, while numerous tech infrastructures built atop AWS—including Vercel, V0, and DigitalOcean integrations—reported cascading failures. For many developers and businesses, the sudden inaccessibility of cloud APIs, databases, and content delivery services revealed just how concentrated global computing power has become. Even companies not directly hosted on AWS felt indirect pain, as interdependent networks and shared authentication services buckled under the strain.
At the heart of the problem was AWS’s US-East-1 region, one of the company’s oldest and most heavily used data center clusters. According to AWS’s post-incident reports, an internal DNS system malfunctioned, interrupting name resolution and routing between key services, including DynamoDB and EC2 control planes. When internal network monitoring tools themselves became affected, the outage escalated faster than engineers could isolate the issue. In highly interconnected systems like AWS, even a localized fault can spiral into global instability—a reality this event made painfully clear.
The business impact was staggering. Thousands of companies—ranging from gaming studios to fintech platforms—saw their operations grind to a halt. For some e-commerce and banking services, the outage meant lost transactions during peak morning hours, while for others, it damaged user trust. Analysts estimate that the total cost of the disruption reached into the hundreds of millions of dollars in lost productivity, revenue, and remediation expenses. Beyond the financial blow, the event reignited debate about the systemic risk of cloud centralization, where a single provider’s outage can effectively pause large swaths of the internet.
For cloud-reliant organizations, the outage underscores several crucial lessons. First, multi-region architecture is not optional—it’s essential. Relying solely on one region or availability zone creates a single point of failure. Second, businesses must design for graceful degradation, ensuring that critical functions remain operational even when dependencies fail. Third, transparency and communication are vital. Customers are far more forgiving of downtime when companies are upfront about what’s happening and how they’re responding. Finally, resilience is not a one-time investment—it’s an ongoing discipline of monitoring, testing, and improvement.
At CodeCraft Studios, we view this event as a call to action for every technology-driven company. Preparing for outages is not about avoiding the inevitable; it’s about engineering confidence into your systems. That means conducting regular failover drills, implementing infrastructure-as-code to redeploy quickly across regions, caching essential services to maintain partial functionality, and running chaos-engineering exercises to expose weak points before they become failures. Just as importantly, it’s about fostering a culture that treats downtime not as an embarrassment, but as an opportunity to learn and strengthen.
Looking ahead, the AWS outage will likely prompt deep introspection within Amazon itself. Expect investments in redundancy, faster internal detection, and perhaps more granular regional isolation to prevent cross-service cascade effects. Across the cloud industry, the incident will accelerate trends toward multi-cloud and hybrid-cloud strategies, as enterprises seek to mitigate vendor lock-in. Regulators and enterprise customers alike will demand clearer transparency and stronger uptime guarantees. In the long run, this disruption might make cloud computing more robust, distributed, and accountable—but only if the industry embraces the lessons learned.
The October 2025 AWS outage was more than just a service disruption—it was a stress test for the modern internet. It revealed both the fragility and the strength of our interconnected systems. For developers, startups, and enterprises alike, it’s a reminder that resilience isn’t built in the cloud—it’s built in the mindset of those who depend on it.
What Happened: The AWS Outage Timeline
Here’s a rough timeline of the incident:
- According to reporting, the trouble began at approximately 3:11 a.m. ET (12:11 a.m. PDT) on Monday, October 20, 2025. AP News+2 [Tom's Guide]
- Users worldwide started reporting outages for numerous services. By around 1:26 a.m. PDT (4:26 a.m. ET), AWS had identified a significant issue with one of its services (e.g., its DynamoDB endpoint) in its US-East-1 region. [Tom's Guide]
- A fix was deployed at about 2:22 a.m. PDT (5:22 a.m. ET), with gradual restoration of services starting then. [Tom's Guide]
- AWS stated that the underlying DNS (Domain Name System) issue had been “fully mitigated” by around 6:35 a.m. ET. [The Washington Post]
- Some services remained degraded for a while, processing backlogs or facing elevated error rates even after the main fix. [WIRED]
In short: early pre-dawn U.S. time, major hit in AWS’s US-East-1 region, mitigation within a few hours, full clean up thereafter.
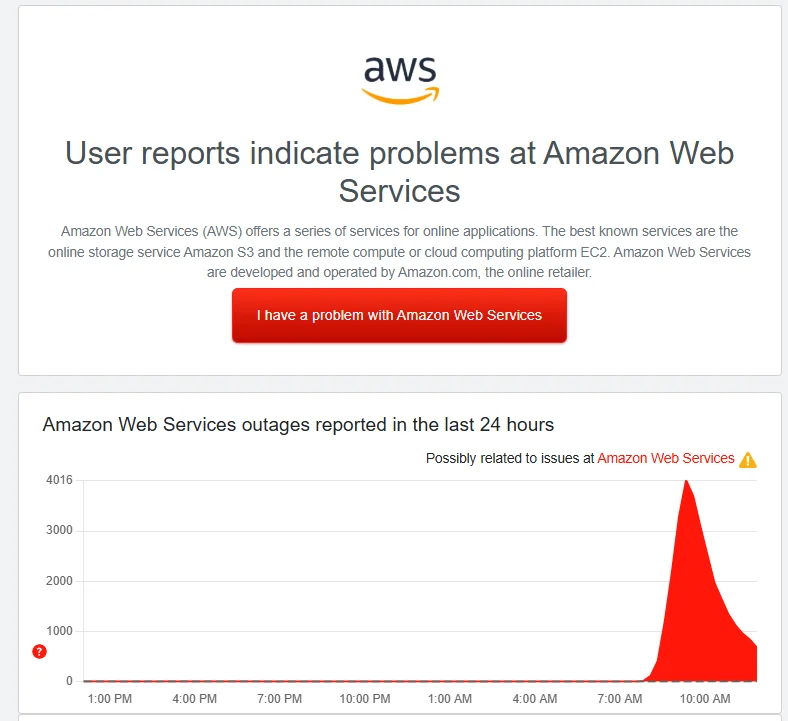
Major Websites and Platforms Affected

Because AWS underpins a huge portion of the internet’s infrastructure, many well-known apps and services reported issues:
- Gaming platforms like Fortnite were impacted. [Reuters]
- Social / messaging: Snapchat had widespread reports. [AP News]
- Payment/fintech platforms: Venmo, Robinhood Markets (via indirect reporting) suffered service disruptions. [Newsweek]
- Other widespread services: gaming (Roblox), consumer apps (e.g., Wordle), banks (UK banks like Lloyds Bank, Bank of Scotland). [Data Centre Magazine]
This mass‐impact is what made the outage headline-worthy.

The Technical Breakdown: AWS Region and Root Cause
Here are the more technical specifics of what went wrong:
- The incident was centred in AWS’s US-EAST-1 Region (Northern Virginia). [Statesman]
- The root cause: AWS cited an “underlying DNS issue” which led to elevated error rates and latencies for multiple AWS services in that region. [AP News]
- More specifically, reporting suggests the issue affected the health/monitoring subsystem for network load balancers, and the service for launching new EC2 instances was also impaired. [Tom's Guide]
- A critical data service affected was Amazon DynamoDB (AWS’s managed NoSQL database); AWS noted “significant error rates for requests made to the DynamoDB endpoint in US-EAST-1”. [Data Centre Magazine]
- Although the data centre cluster is massive and designed for resilience, a failure in a core monitoring or control subsystem created broad cascading effects. As one article put it: “When domain name resolution stops working, entire applications and services can stop responding, no matter how well they are designed.” [Newsweek]
In effect: a fault in a backbone piece of infrastructure (DNS + internal load-balancer health monitoring) in a major region caused massive ripple effects.
Business Disruption at Scale: Global Impact
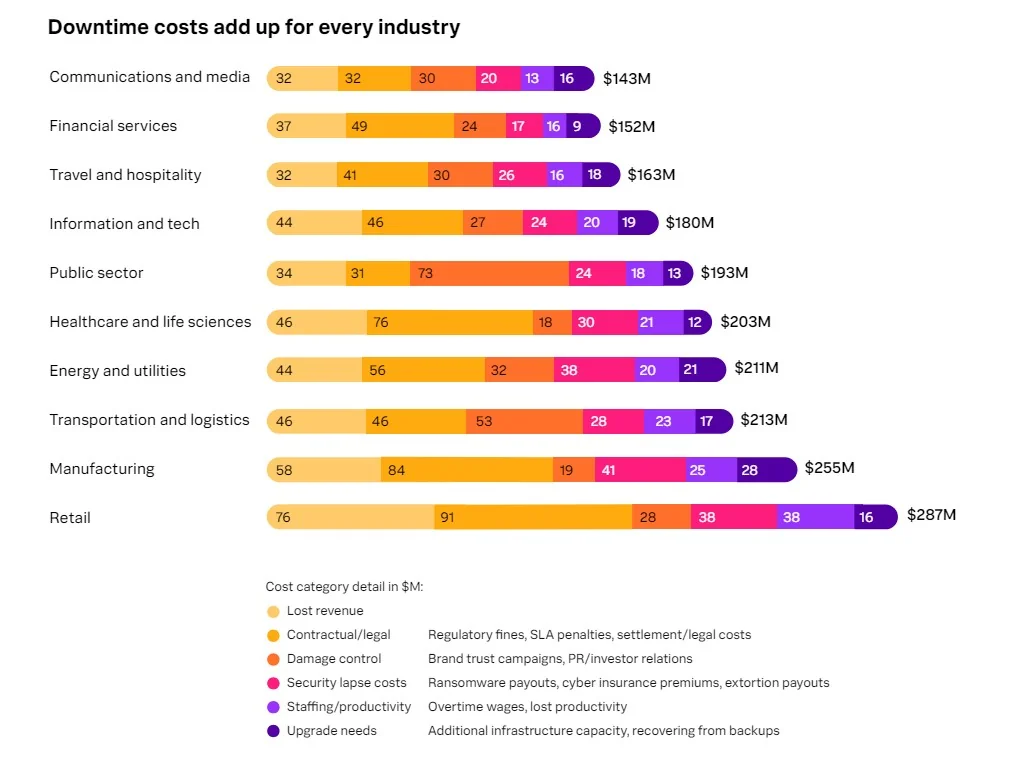
The fallout for businesses and users was significant:
- Reports show millions of outage incidents registered worldwide across many countries. [LinkedIn]
- Industries impacted: gaming, social media, fintech, banking, e-commerce, streaming, enterprise cloud tools. A single issue in AWS rippled across verticals. [Data Centre Magazine]
- Financial impact: Some commentary estimated hourly losses in the tens to hundreds of millions of dollars due to service disruption, lost transactions, productivity, reputational damage. [Tom's Guide]
- For regulated industries (banks, government services), the outage raises concerns about compliance, availability, business continuity. [Data Centre Magazine]
- The event underscores one major risk: single-region dependency. When a dominant region for many services fails, the consequences are global — not just local.
For businesses (especially those relying on cloud services), this is a wake-up call: your cloud provider’s failure is your failure.
Lessons for Cloud-Reliant Companies
Here are actionable take-aways any organisation that relies on the cloud should note:
- Multi-region & multi-provider resilience
Don’t assume one region or one provider is enough. Have fallback paths, across regions and ideally across clouds. - Understand your dependencies
Know which services you use (e.g., managed DBs, serverless, DNS) and how they fail. If core services like DNS or load-balancer monitoring go down, there may be broad effects. - Design for degraded performance, not just full outage
Some services continued but with elevated error rates or latency. That still hurts the user experience and revenue. - Plan for fail-over of control/management layers
Outages often start in control systems (health monitoring, load-balancer metrics, DNS). Make sure you can operate if those are impaired. - Monitor upstream cloud provider health
Use the provider’s status dashboards (e.g., AWS Health Dashboard) and external trackers (e.g., Downdetector) to detect early signal of trouble beyond your service. - Communicate clearly to customers
When your service goes down, being transparent, proactive, and empathetic helps mitigate reputational damage. - Test outage scenarios regularly
Run drills: simulate region failure, DNS failure, provider API throttling. See how your systems respond. - Have business continuity & SLA-aware contracts
If you rely on cloud, make sure your business continuity plans reflect major cloud provider outages and that contracts/SLAs account for risk.
CodeCraft Studios Insights: How to Prepare for Cloud Outages
For an organisation like CodeCraft Studios (or similar mid-sized/cloud-native companies), here is a tailored set of preparations:
- Inventory your cloud footprint: Map out all services you consume from AWS (or other clouds), and identify which region(s) and availability zones (AZs) you rely on.
- Define your maximum tolerable downtime (MTD) & maximum tolerable data loss (MTDL): How long can you be down? How much data can you lose and still operate?
- Implement region-agnostic architectures: For example, deploy active/active in two regions, or have warm standby in another region. Use multi-region DNS fail-over.
- Use infrastructure as code (IaC): That way, you can provision in an alternate region quickly if needed.
- Use managed services but with fallback: If you use DynamoDB (in one region) and it goes down, consider global tables or fallback to another DB.
- Cache dependencies and fail-gracefully: Ensure your app degrades gracefully if dependent services are slow or unavailable.
- Chaos-test your architecture: Introduce failures (region, service, latency) and measure recovery.
- Communicate with your users upfront: If you have customers, show that you are cloud-resilient and what your fail-over plan is.
- Track cloud provider status and alerts: Subscribe to AWS Health Dashboard, follow provider blogs and social channels.
- Review your incident post-mortem: After an incident (even minor), document root cause, impact, lessons learned, action items. Use it to improve.
In short, think of cloud outages not as “if” but “when” — design accordingly.
Looking Ahead: What This Means for AWS and the Industry
Here are some broader implications:
- For AWS: This outage will likely prompt internal reviews and perhaps changes to architecture, redundancy, monitoring, and how quickly it communicates issues. It may also impact customer trust — especially among enterprise clients demanding higher SLAs and transparency.
- For the cloud industry as a whole:
- Reinforces the fact that despite the vast size and sophistication of hyperscale clouds, they can fail, and when they do the effects ripple globally.
- May accelerate adoption of multi-cloud or hybrid-cloud strategies. Companies might seek to avoid being “locked in” to one provider’s failures.
- Will raise the bar for resilience: providers will need to better isolate failure domains, improve cross-region fail-over, and make their status communications even more timely and clear.
- Could influence regulation (especially for critical infrastructure, financial services, government) around cloud provider dependencies, resilience, auditability.
- For customers: There will be renewed attention to cloud-resilience. Customers may demand stronger contractual guarantees, more transparency, and better incident response from providers.
- On the internet’s architecture: The concentration of so many services on only a few cloud providers (AWS, Microsoft Azure, Google Cloud) is both a strength (scale, innovation) and a systemic risk (failure of one provider reverberates widely). This event re-highlights that tension.
Conclusion
The October 20, 2025 outage at AWS (US-EAST-1) is a strong reminder that even cloud-giant infrastructure can fail — and when it does, countless businesses (big and small) feel the effects. For organisations such as CodeCraft Studios (and anyone building on the cloud), the lesson is clear: design for failure, distribute risk, prepare in advance, and communicate transparently.